
Building Scalable Data Architectures with Lakehouse
With this blog, let’s break down the concept of a data lakehouse and its uniqueness regarding data lakes vs. warehouses while exploring the benefits associated with Spiral Mantra data engineering services, with potential architecture explained! Since times have changed, data has become potent for every business. It is now crucial for organizations to start utilizing lakehouses (bringing together the best capacity of data warehouses + lakes) for effective management and scale. Platforms like Snowflake, AWS, and Spark have exponentially started capturing the market with their amazing information management paradigm, favoring professionals with a way to centralize information with other streamlining benefits.Let’s Unveil What is Data Lakehouse?
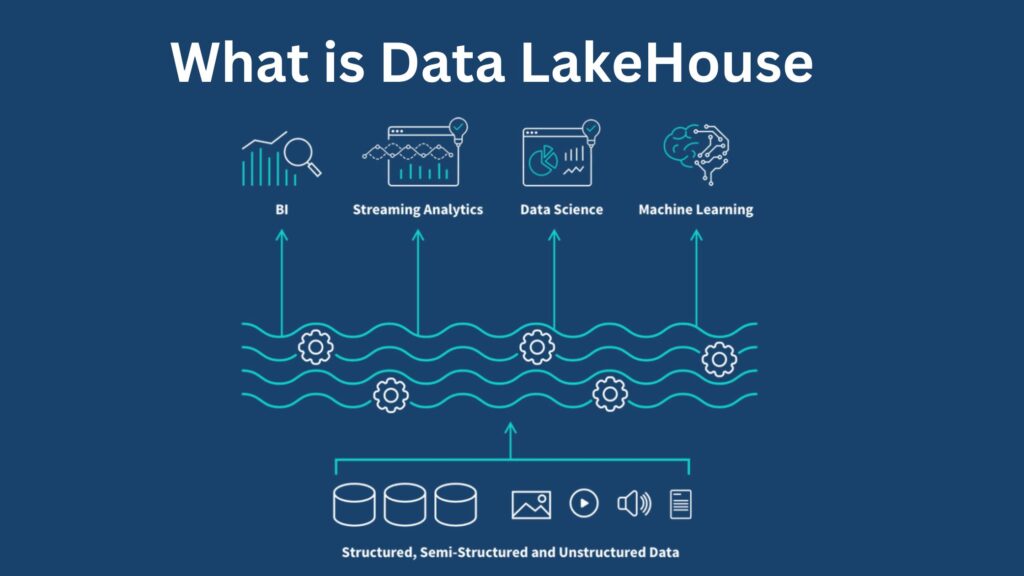 A data lakehouse is a modern statistics management architecture combining the low cost, scalability, and flexibility of storing a diverse range of file types inherent to information lakes with a data warehouse's performance, governance, and reliability features.
To be precise, a data lakehouse tool like Snowflake merges the best functionalities to store and analyze any form of information and compile it to get intelligent action. The platform came into action by facilitating reliable features, including.
A data lakehouse is a modern statistics management architecture combining the low cost, scalability, and flexibility of storing a diverse range of file types inherent to information lakes with a data warehouse's performance, governance, and reliability features.
To be precise, a data lakehouse tool like Snowflake merges the best functionalities to store and analyze any form of information and compile it to get intelligent action. The platform came into action by facilitating reliable features, including.
- Agnostic support for every file type: PNG, TXT, CSV, parquet, etc.
- Allowing flexibility to vendors to work impeccably with file formats like ORC and Iceberg and compute engines like SQL, Scala, Python, or R.
- Prioritize quality by enforcing validation rules to define structures.
- Unifying AI adoption to extract rich metadata by enforcing maximum security controls on compute resources.
The Major Differentiation Between Data Lakehouse vs Lakes vs Warehouses
As we talked about earlier, the term lakehouse combines the repositories and capacity of a lake and a warehouse, allowing engineers to get the analysis and reports done efficiently.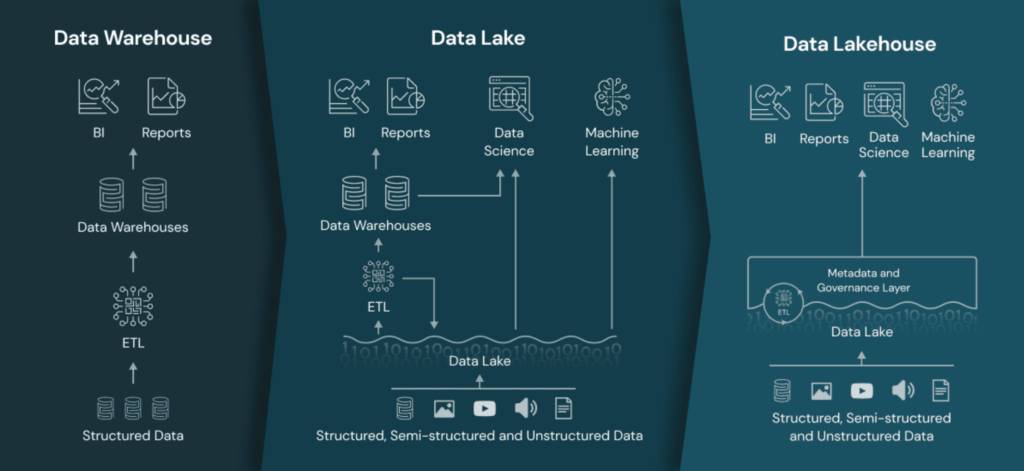 Image Source by Databricks
Image Source by Databricks
Data Warehouse
Foster to accelerate fast access to raw information and SQL compatibility for organizations in use to generate reports for authoritative decision-making. In this manner, all the extracted information undergoes the ETL phase, dedicated to optimization in an explicit format before being loaded to sustenance high-performance queries.Data Lakes
Known to store big data in its native format, unlike warehouses, lakes process information, clean it up, and then convert it for analysis to qualify quicker loading speeds. The process is ideal for accomplishing predictive analysis with the help of ML algorithms. However, the process requires expertise only, setting limits to the use of the information in the long run; it also deteriorates the quality over time.Data lakehouse
Amalgamates the two methods to optimize and create a single structure, allowing the leverage of unprocessed information for many purposes. Executing from BI to machine learning, Lakehouse captures all your company’s information and applicably implicates in low-cost storage by facilitating capabilities to explore and organize data as per the firm’s needs.Major Challenges and Working Mechanisms of Data Lakehouse
 Before starting to learn how Lakehouse works, make sure to understand its challenges first, as it comprises new architecture; thus, its best practices are still evolving and can cause an excruciating issue with the early adopters. Additionally, they can include the complexity of building from scratch, especially if you are an amateur. In major cases, you either need to get along with an out-of-the-box solution or need components to back open architecture streams.
Considering the working mechanism of Lakehouse, it aims to consolidate disparate information sources while streamlining engineering efforts so that everyone in your office can access unified information about changes and decisions. Tools like Snowflake and Google BigLake facilitate on-demand, low-cost cloud object storage for easy grading. Unlike a data lake, it can seize and stockpile big data in raw form.
The lakehouse joins in with meta layers providing warehouse-like competencies, which include the list of ACID transactions, structured schemas, and major optimization features with the support of governance and management.
Before starting to learn how Lakehouse works, make sure to understand its challenges first, as it comprises new architecture; thus, its best practices are still evolving and can cause an excruciating issue with the early adopters. Additionally, they can include the complexity of building from scratch, especially if you are an amateur. In major cases, you either need to get along with an out-of-the-box solution or need components to back open architecture streams.
Considering the working mechanism of Lakehouse, it aims to consolidate disparate information sources while streamlining engineering efforts so that everyone in your office can access unified information about changes and decisions. Tools like Snowflake and Google BigLake facilitate on-demand, low-cost cloud object storage for easy grading. Unlike a data lake, it can seize and stockpile big data in raw form.
The lakehouse joins in with meta layers providing warehouse-like competencies, which include the list of ACID transactions, structured schemas, and major optimization features with the support of governance and management.

