
Detailed Comparison of Data Mesh vs Data Fabric
As businesses grew, managing their changing data becomes a complex affair. Because traditional architectures break under the weight of decentralized teams, compliance pressures, and the demand for real-time access. This is where data engineering company takes modern approaches like Data Mesh and Data Fabric integration.
In today's blog, we'll be discussing how these two overcome the complexity of today's sprawling data ecosystems.
Data Mesh & Data Fabric Explained
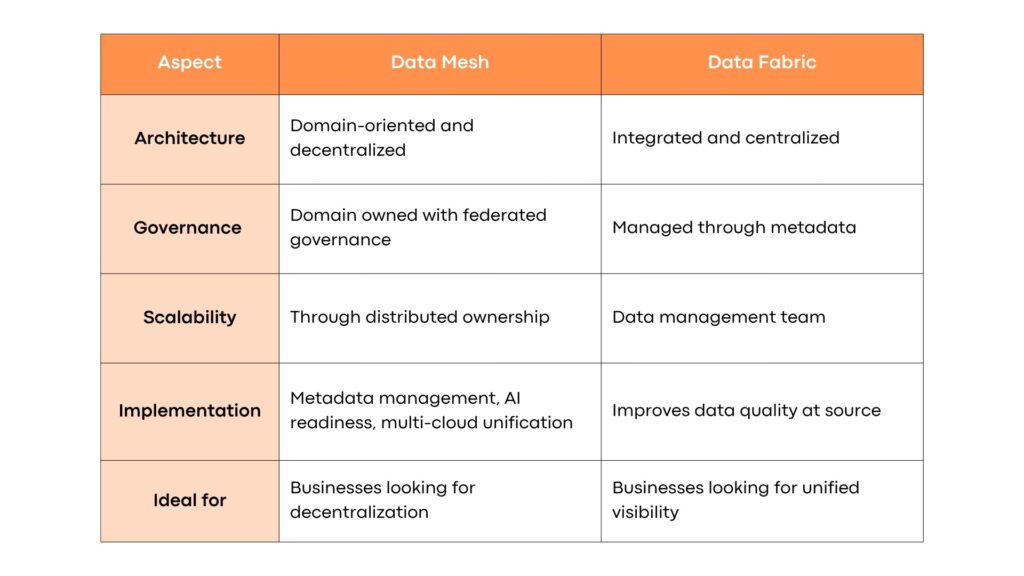
At their core, data mesh and data fabric differ in orientation. While data fabric automates and unifies data management and data governance, data mesh decentralizes domain ownership.
But both rely heavily on metadata, even if for different reasons.
Now, let’s take a detour and understand what metadata is first!
Metadata is the foundation of every data strategy today. It captures the who, what, where, when, and how of every data asset, providing context for digital assets.
But metadata is difficult to wrangle because it lives scattered across various databases (spreadsheets, emails, etc.). And humans cannot realistically manage such metadata volumes.
What is data fabric?
This is an architectural design concept that uses active metadata and automation to support integration and well-governed data access across all environments.
Gartner emphasizes that data fabric is not a single product but a composable architecture made of interoperable technologies connected by metadata collection.
In simple words, a data fabric weaves together all your data sources into a single intelligent layer, making it easier to find data.
Its important characteristics include:
Single data control and management
Automated data integration and discovery
Data cataloging, AI-driven metadata
Live data availability across all environments
Strong governance
It's popular in:
Enterprises managing a hybrid or multi-cloud environment
Fintech with compliant data sharing needs
Healthcare organizations looking for integrated patient data
What is data mesh?
It is a decentralized data architecture where domain teams own, manage, and deliver data as a product. Unlike data fabric, data mesh scales by decentralizing responsibility across various domains. It rests on four foundational principles, i.e., data as a product, decentralized ownership, self-service data infrastructure, and computational governance.
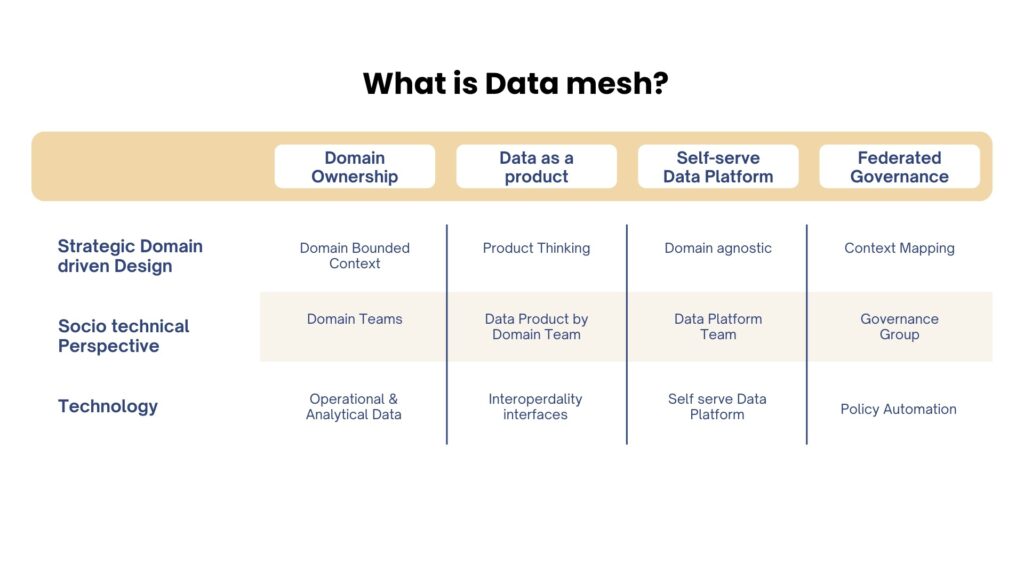
Its important characteristics include:
Domain-oriented data ownership
Data governance
Collaboration and accountability
Self-serve data infra for teams
It's popular in:
Large business with many units
Businesses aiming for data democratization
Companies in need of agility with scalability
Core Differences of Data Mesh vs Data Fabric
Although complementary in nature, both data mesh and data fabric differ in ownership, governance, and architecture. Here is how the two compare at a glance:
See Why You Need Data Fabric & Data Mesh
Data Fabric
Large organizations have architectures across different systems, clouds, APIs, and formats. Data fabric unifies, manages, and secures this data, allowing businesses to ensure regular governance.
Here’s why businesses are looking to adopt data fabric:
Singular governance with security: Ensures compliance with data protection policies that benefit the business.
Cost effectiveness: Its scalable architecture improves resource utilization while reducing overhead cost
Better data management: Metadata automates data integration, discovery, and cleansing, reducing manual work.
Overcome complexities: Availability of data from various sources in one place removes complexity.
Data Mesh
As data volumes and demands grew, centralization created bottlenecks and bad quality output. Data mesh responded to this with a centralization approach. And decentralizing, shifted ownership to experts, improving data quality and overall performance.
Here’s why businesses are looking to adopt data mesh:
Reduce bottlenecks: Shifting ownership to experts helped improve performance as well as data quality
Improve data operations:The distributed ‘mesh’ manner helped businesses handle large volumes of growing data easily
Improve value performance:Easy consumption of data improved the time taken to get insights from data.
Personalization:Teams tailor data management according to their needs, reducing the complexity of monolithics
Can Data Mesh & Fabric Work Together?
Most successful businesses do not choose one over the other, but a careful combination of both.
According to independent research, embracing a hybrid approach provides metadata intelligence, automation, and better decision-making. Together, these capabilities encourage clear ownership, better data access, and sharing across multiple domains.
Conclusion
To sum up, in 2026, there is no clear winner between data mesh and data fabric. Because the answer lies in the business’s data maturity, culture, and operational model.

Commonly Asked Question
Which approach is better for my business?
How long does implementation take?
Can both data mesh and data fabric be used together?
Which industry benefits from data mesh/data fabric?
Which data architecture will move my business in 2026?
At Spiral Mantra, we advise a balanced approach that combines the strength of both. But in reality, it depends on your business needs. While data mesh works for large companies where teams have technical skills, data fabric architecture works best where one needs centralized rules.
Data mesh usually requires anywhere between 6 and 12 months for implementation. While data fabric can go live in a few weeks if supported by knowledgeable tech teams. Connect with our experts to get a better overview of your business case.
Yes. Large businesses use both data mesh and data fabric together for better results.
Financial services or businesses with complex data benefit from data mesh. Healthcare and manufacturing businesses with data spread across many cloud providers benefit from a data fabric.
According to the trend, 61%* businesses think that mixing both data mesh and data fabric will help their business. However, it is best to evaluate your business needs first before deciding this.

