
Explore how Apache Iceberg enables ACID-compliant Data lakes
Modern data lakes often suffer from "data swamps" (referring to an unorganized repository due to a lack of governance, metadata, and data quality standards). This is due to a lack of governance, which results in poor data quality, less searchability, and security risks.
Other challenges include high maintenance costs and slow query performance due to unoptimized raw data storage. Transforming “data swamps” into functional, production-ready repositories demands clear data lifecycle policies, automated data quality checks, robust metadata management, and modern table formats.
In this blog, we explore how Apache Iceberg enables ACID-compliant data lakes, mitigates small-file bottlenecks, and how Spiral Mantra works closely with engineering teams to design, implement, migrate, and optimize modern data lake platforms that support ACID transactions and high-performance analytics.
What is ACID?

ACID stands for Atomicity, Consistency, Isolation, and Durability. These are four foundational properties that ensure reliable transactions in relational databases:
Atomicity means that a transaction is all or nothing. Either all changes are committed, or none of them are, leaving no room for half-written or partially applied data.
Consistency ensures that any transaction will bring the system from one valid state to another, maintaining all rules such as schema constraints, data types, and referential integrity.
Isolation guarantees that concurrent transactions don't interfere with each other, avoiding race conditions, dirty reads, or inconsistent snapshots.
Durability means that once a transaction is committed, it will persist, even in the face of system crashes or power loss.
These properties are important for applications that rely on trustworthy and synchronized data, such as financial systems, real-time analytics, and ML pipelines.
Why ACID is Useful in Data Lakes?
Traditional data lakes were append-only storage systems. However, modern data platforms support updates, deletes, streaming ingestion, backfills, and concurrent analytics workloads. Once mutation becomes part of the system, transactional guarantees become essential.
Now, let’s understand how ACID helps in solving common enterprise challenges.
GDPR requires complete and atomic removal of user data. Without atomicity, partial deletes could leave residual records, creating compliance risks.
Data corrections require updating historical records safely. Without isolation and atomic commits, updates may duplicate rows or overwrite valid data.
Late-arriving records require merging new data into existing partitions. Without consistency guarantees, schemas may drift, or conflicts may occur between two writers.
Continuous updates from streaming and batch pipelines often happen simultaneously. Without isolation, concurrent jobs can interfere with and corrupt table state.
If a correction job fails halfway or two jobs overwrite each other’s changes, dashboards, reports, and ML models can reflect inconsistent data. ACID guarantees ensure that updates are applied completely and safely, preserving trust in analytics systems.
Apache Iceberg—Explained
Apache Iceberg is an open table format designed for large analytical tables and datasets. It was designed to solve the shortcomings of Hive-based data lakes by introducing a transactional metadata layer on top of columnar file formats.
So instead of relying on the directory structure and file naming conventions (as in Hive), Apache Iceberg maintains versioned metadata trees that describe the complete state of the dataset at any point in time. This shift in architecture allows it to deliver reliable ACID transactions, schema evolution, partition evolution, time travel, and engine independence.
Interesting fact: Apache Iceberg was co-created by Netflix and Apple and later donated to the Apache Software Foundation
Here’s how it helps modern data workflows:Iceberg supports schema evolution. As data evolves, it allows users to easily add, drop, or rename columns in a table without rewriting the entire dataset. This flexibility lets organizations adapt to changing data requirements and avoid costly data migrations.
Apache Iceberg enables time travel. This means users can go back and check historical versions of a table. This is very useful for auditing, debugging, and reproducing results.
Apache Iceberg also provides optimization features that improve query performance for lakehouses. An example of such data compaction is merging small data files into larger ones, reducing the number of files that need to be scanned every time there is a query execution. Other than that, Iceberg also supports partition pruning, which lets queries skip irrelevant partitions, reducing the amount of data that needs to be processed.
Lastly, Iceberg also supports ACID transactions, which ensure data consistency and reliability. With ACID transactions, multiple users can read and write data to the same table without the fear of data corruption. This comes in handy in data lake or lakehouse environments where data is constantly being accessed by many users.
These features help developers build robust pipelines, automate CI/CD workflows, and bring in agility to manage analytical datasets.
How Apache Iceberg Implements ACID
Metadata as the core engine
Apache Iceberg achieves ACID by separating the logical state of a dataset from its physical data files. This is done through multiple layers of metadata. Let's take a look at them now:
Table Metadata File: This is a data-about-data file that stores structural and technical details about a specific data table, separate from the actual raw data. It typically stores the table's schema, partitioning, sort order, and snapshot history
Snapshot Metadata: Each write creates a new snapshot. The snapshot contains properties like obtaining creation time, file locations, permissions, and structure, without duplicating the actual data
Manifest Lists & Manifests: It contains structured metadata records, lists of data files, partition stats, and deletion information. These are the only sources of truth for what’s in the table.
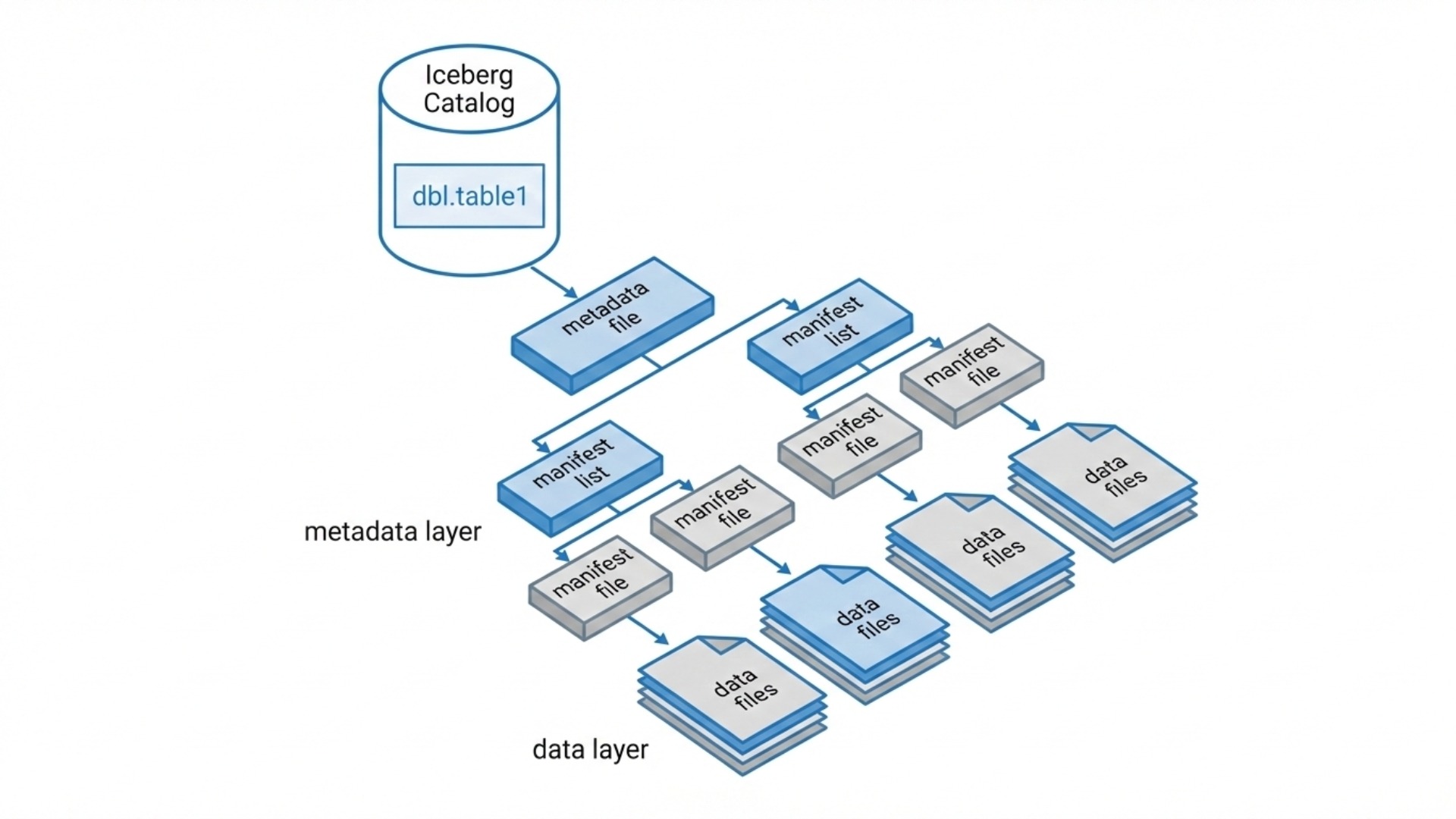 How a write works
How a write works
When a developer runs an operation like INSERT, MERGE, or DELETE, Iceberg follows a precise execution flow. This is how the process works:
1. New data files are written (typically Parquet, ORC, or Avro).
2. New manifest files are generated that reference those data files.
3. A new snapshot is created pointing to those manifests.
4. A new table metadata file is generated referencing that snapshot.
5. The metadata pointer file is atomically updated to point to the new metadata version.
6. Only the final metadata pointer replacement makes the transaction visible.
Atomic Commit
Apache Iceberg uses an atomic compare-and-swap model. So when a write job wants to commit changes:
It reads the current metadata file.
It generates a new snapshot with updated manifests.
It attempts to commit by updating the pointer to the new metadata file.
If the metadata pointer was changed in the meantime or another job was committed, the write fails and retries. This method ensures data integrity and consistency, even in the event of system failures.
Isolation & Concurrency Control
These are fundamental database concepts that ensure data integrity even when multiple transactions happen simultaneously. Isolation ensures transactions appear to run in parallel, while concurrency control (like locks or timestamps) enforces this separation to avoid data inconsistencies.
Here’s what happens when two writers operate simultaneously:
1. Writer A reads metadata version 10.
2. Writer B also reads version 10.
3. Writer A commits successfully & table moves to version 11.
4. Writer B attempts to commit & fails because the base metadata version has changed.
5. Writer B must refresh metadata and retry.
This action prevents unwanted overwrites and corrupted table state.Even if another write occurs during execution, readers still see a consistent snapshot.
Why This Matters
By reducing transactions to a single atomic metadata update, Iceberg enables ACID guarantees on distributed object storage. It allows engineering teams to run streaming, batch, analytics, and compliance workloads on shared datasets without risking corruption or inconsistency.
For organizations building production-grade lakehouse platforms, Iceberg becomes a foundational layer that combines scalability with transactional integrity.
At Spiral Mantra, a data engineering services company, our teams design and implement Iceberg-powered architectures that handle real-world production workloads, ensuring optimized ingestion strategies, controlled concurrency, and long-term performance sustainability.


