
An Introduction to Data Vault 2.0
Businesses today generate a lot of data. Yet many organizations still rely on traditional data warehouse models that are unable to keep up with fast-changing data sources.
The problem starts when frequent schema changes, slow data integration, and limited historical tracking make these architectures difficult to scale. Data vault modeling addresses these challenges, and that’s why most businesses are willing to adopt it today.
In this blog, we'll discuss what a data vault is and how a data engineering company can assist.
What is a Data Vault?
Created by Dan Linstedt in the 1990s, data vault is a data modeling methodology used to design modern data warehouses that can handle large data, frequent schema changes, and multiple data sources.
This approach emerged from the need to handle rapidly changing business environments and increasing data complexity that traditional warehousing methods struggled to accommodate.
The core principle of data vault focuses on building a flexible, auditable foundation that can absorb new data sources and business rule changes without disturbing existing structures.
In short, data vault creates a business-wide integration layer that preserves all data history, which allows businesses to maintain a complete audit trail of how their data has changed over time.
What Makes Data Vault 2.0 Different?
Data vault 2.0 is an open-source extension, refined from the previously launched data vault 1.0. This was introduced by Dan Linstedt and Michael Olschimke in 2013.
Here are some of its characteristics.
Hash keys: DV2.0 introduces hash keys derived from business keys. This allows parallel data loading, faster processing, and better processing in distributed systems.
Methodology, architecture, modeling: Unlike DV 1.0, data vault 2.0 provides a comprehensive framework, combining modeling, architecture, and methodology:
Modeling:
maintains hubs (keys), links (relationships), and satellites (history).Architecture:
Defines the data warehouse. It consists of a staging area, raw vault, business vault, and information mart.Methodology:
Introduces agile practices that speed up the implementation of changes and rapid business needs.
Better performance: Use of hash keys and parallel processing allows handling of large data volumes and enables fast data warehouse expansion without complex refactoring.
In short, data vault 2.0 is designed for agile data warehousing, turning away the focus from mere data modeling to an automated, and audit-ready ecosystem.
Data Vault Modeling: Hubs, Links, Satellites
Data vault has three entities: Hubs, Links, Satellites.
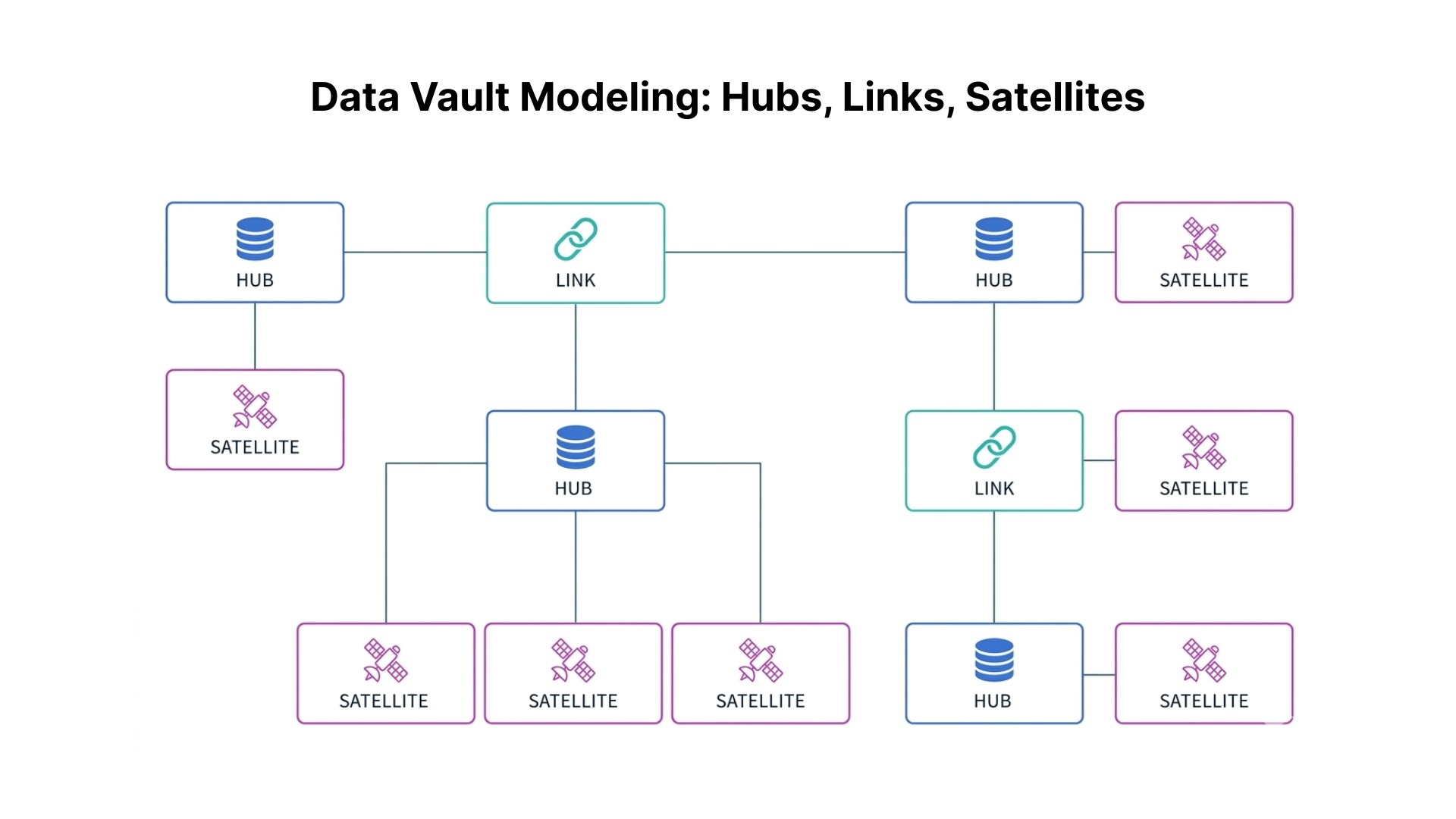
Hubs: represent a core business entity like a customer, product, or store.
Each Hub contains only a business key, a hash key for performance, a load timestamp, and a record source. This minimal structure ensures that Hubs remain stable even as business rules and descriptive attributes change.
This key focus is what makes Hubs so powerful and enduring. For example, a customer Hub might store customer numbers, a product Hub contains product codes, and a location Hub holds store identifiers. These keys rarely change, making them traceable for a lifetime.
Links represent the relationship between Hub entities.
A link table contains the hash keys from its related Hubs, its own hash key, plus the standard metadata fields.
Like Hubs, Links contain no descriptive attributes; they purely represent that a relationship exists.
For example, Links connect to multiple Hubs, representing complex business relationships. For example, a customer purchased a product at X location using a promotion.
Satellites: store all the descriptive information about Hubs and Links, providing detailed information about business entities and their relationships.
The true power of satellites lies in their ability to trace historical changes.
For example, when a customer changes address, the old record with an end date remains, and a new record with the updated information begins, making this a critical capability for modern data management.
Data Vault Architecture: How it Works
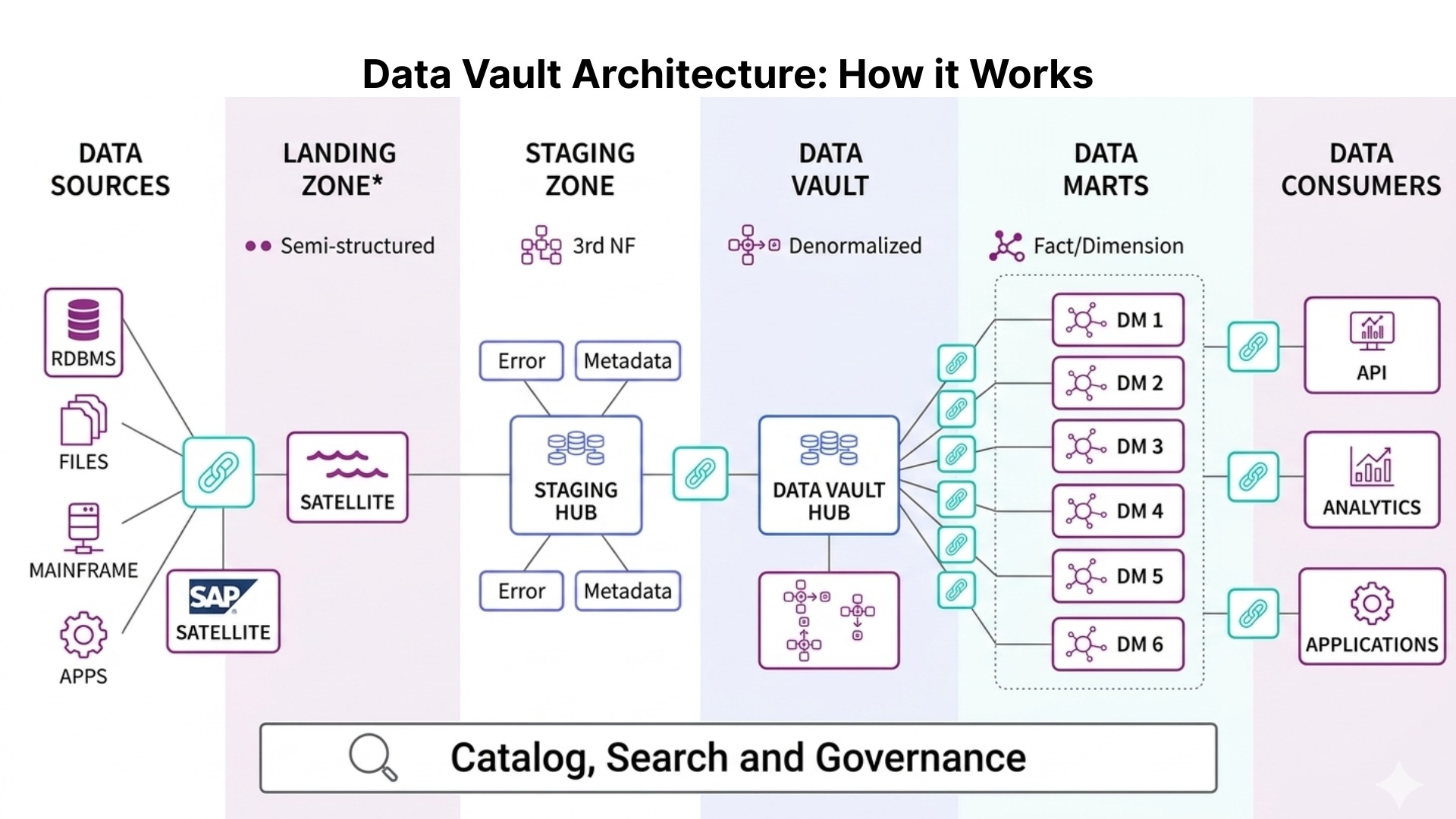
Data vault architecture: organizes data into clear, structured layers that work together from data ingestion to analytics-ready insights. Each layer serves a specific purpose, and understanding how they connect together is important for scalability in the long-run.
Staging area: This is where the data first arrives from an external source. It is designed as a low-processing environment where records are absorbed close to their original form. This prevents premature data manipulation, making it easier to analyze errors between source and stored states. In short, it acts as a controlled entry point that protects downstream systems when changes happen in external systems.
Raw vault: This is the central historical and integration layer of the data vault architecture. It stores data using hubs, links, and satellites without applying business rules, contextual interpretation, or filtering decisions. Its purpose is to retain complete, system-level history that reflects what was received, when it was received, and from which originating source. This makes it possible to answer root-level queries that traditional warehouses struggle to answer, particularly when historical records are reviewed after a long time.
Data mart layer: This layer provides curated and performance-aligned structures for consumption by analysts, reporting systems, and data products. Ideally, its outputs include dimensional models, denormalized tables, and semantic layers designed to support self-service tools. Businesses that adopt a Data Vault approach find that a clear final data layer makes it easier for analytics teams to access trusted data without having to deal with complex data integration structures.
Business vault:Applies business rules, transformations, and calculations to raw data, making it meaningful for downstream consumption.
Real Use Case
A retail company integrated data from multiple sources. Plus, using traditional data warehouses led to frequent schema changes, causing inconsistency while reporting.
Using data vault 2.0, our experts:
Enabled faster integration of new data sources
Made historical tracking doable
Improved analytics for better customer demand prediction
Best Practices for Implementing Data Vault
Implementing a data vault requires alignment with the business’s long-term model.
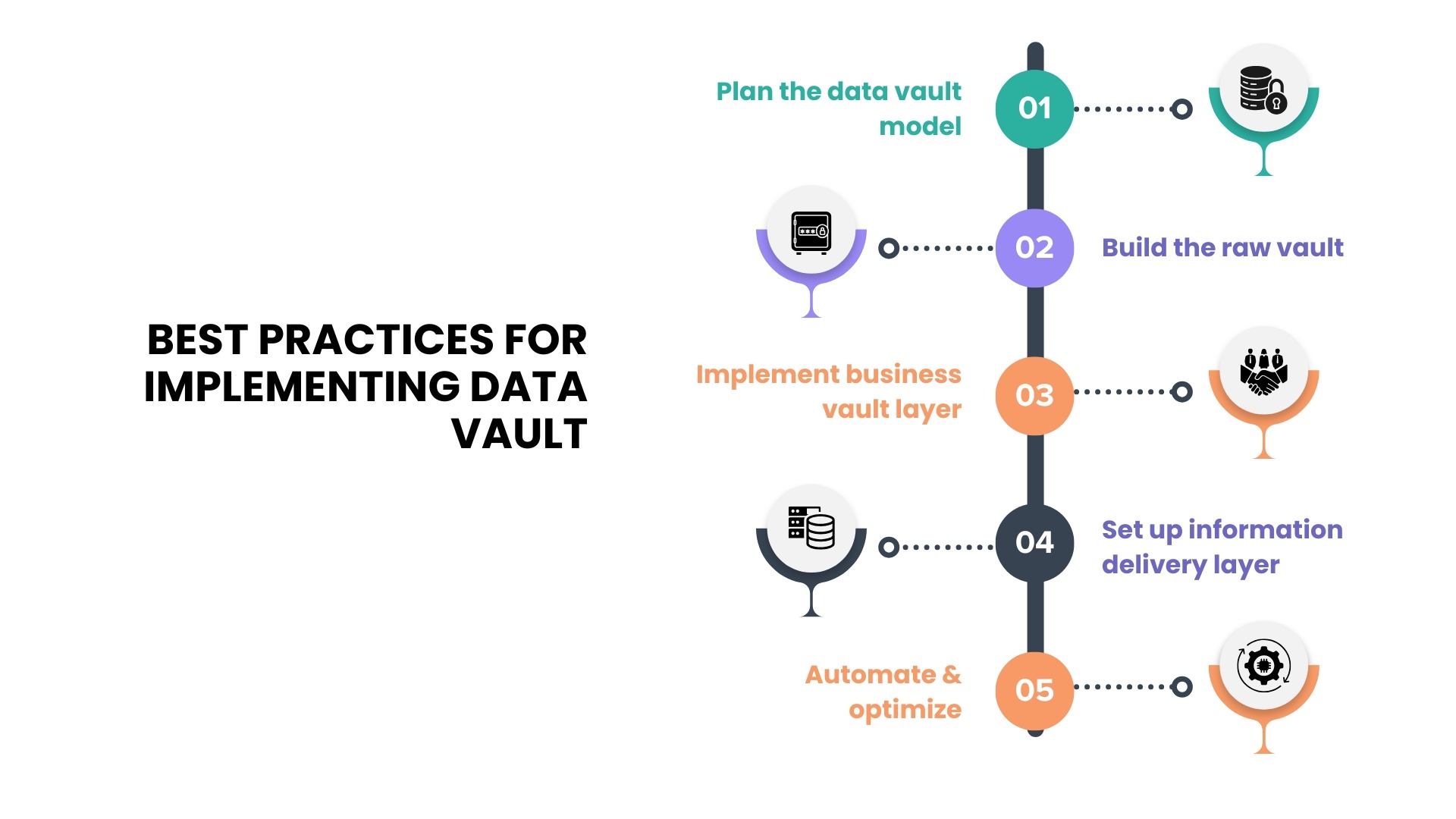
Step 1: This phase focuses on business alignment, i.e identifying which business assets represent long-term concepts rather than application-level constructs. These are suitable for hubs because their identifiers are likely to remain stable even as underlying systems change. Relying on a temporary ID from a single operational system may lead to redesigning later if that system is replaced or integrated with another.
Step 2: At this stage, build raw vault using hubs, links, and satellites. Raw vaults are preserved using extract and load techniques that preserve original values, timestamps, and source information.
Step 3: This stage is about building additional structures in the business vault that apply rules to turn unusable data into meaningful information. Clear documentation and stable development practices are important here because business rules often evolve based on feedback from analytics users.
Step 4: This stage is about presenting data in formats that are best for analysis. The data is then organized into dimensional models, wide tables, or domain-specific views depending on how businesses want to use it. It connects the data vault to the tools used for reporting, dashboards, advanced analytics, and data products that support both business and technical users.
Step 5: Automation As data sources and satellites increase, manual development quickly becomes difficult to manage. That's why automating data workflows, orchestration, and testing helps maintain efficiency and reliability. Data Vault 2.0 promotes metadata-driven automation, where data models and pipelines are generated using pre-defined templates and rules rather than manual coding. This approach ensures faster pipeline development, consistent data modeling, parallel data loading, and scalability. Without automation, the manual efforts slow progress and increase the risk of errors in the data pipeline.
Pro tip: dbt, WhereScape, and VaultSpeed are commonly used to implement data vault 2.0
Benefits of Data Vault Modeling
Data vault provides a solid foundation for building and managing data warehouses in places where data is diverse and subject to change.
The benefits of using this model include:
Flexibility: Data vault’s agile methodologies and techniques are designed to handle changes and additions to data sources with minimal disruption. This makes them well-suited for environments where data requirements change frequently.
Scalability: Data vault's adaptability to handle large volumes of data makes it ideal for businesses implementing a data lake or warehouse solution.
Auditability: Known to maintain traceability of data, the data vault makes it easier to track changes over time.
Easy to maintain: Data vault’s simple process of making new changes or editing old ones reduces time and effort, making it easy to maintain. Plus, it also simplifies the data ingestion process, removing the requirement of a star schema.
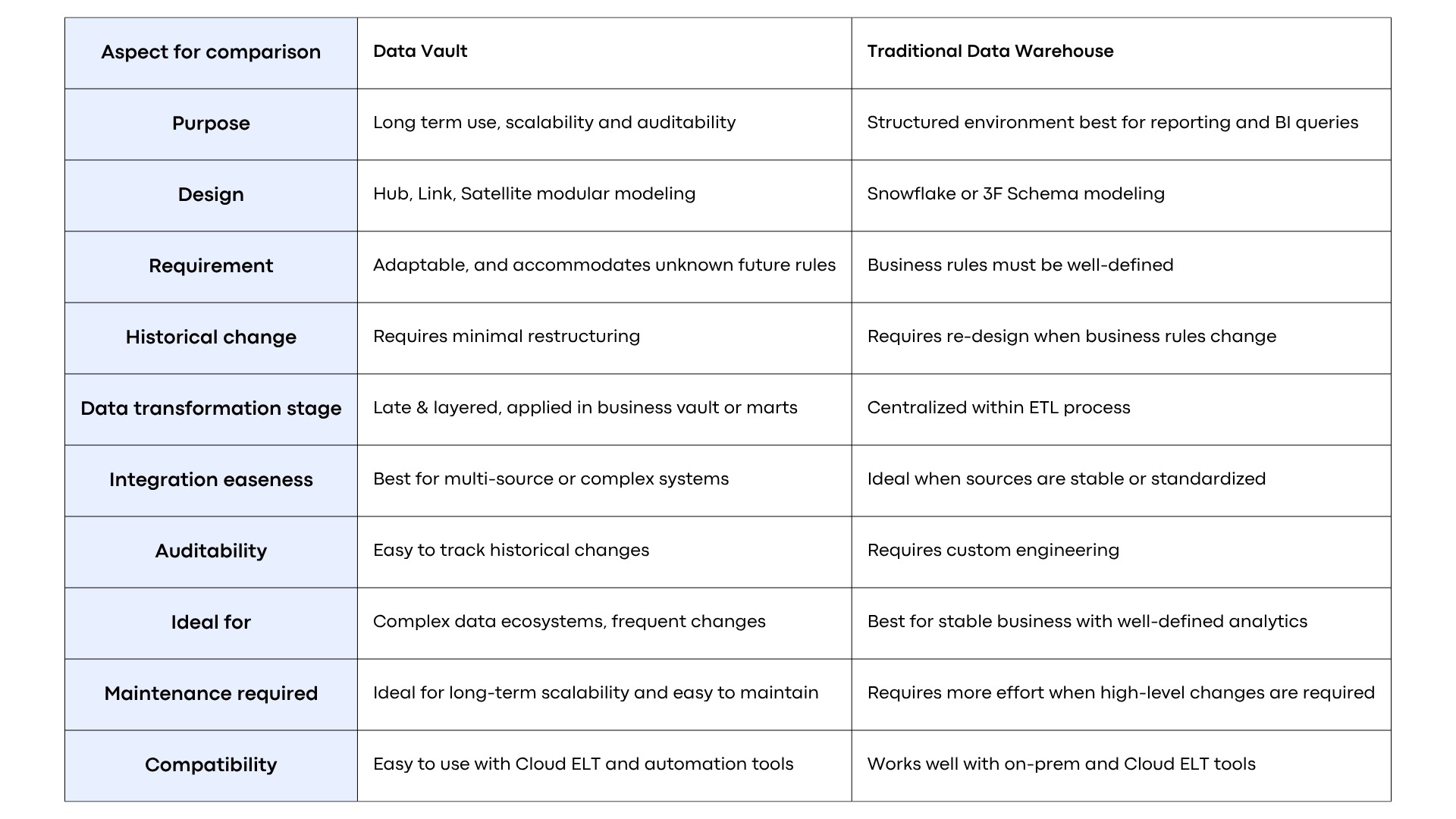
Comparison: Data Vault vs Traditional Data Warehouse
Traditional data warehouses rely on pre-set business rules, meaning effort happens upfront. This means that during reporting, large parts of the model get reworked, causing delays, design cycle, and risk to historical reporting.
Data vault on the other side separates business keys, relationships, and descriptive attributes into independent components. This makes it easier to make new changes, view historical changes, and adapt to changing needs with minimal disruption.
Role of a Data Engineering Company in Modern Data Platforms
According to a 2023 Accenture study, nearly 30% of data will be created by stimulations and AI-driven systems.
This shift means that businesses have more data to handle than they normally do. And without a flexible, fully auditable data foundation; synthetic data can move away from reality, making insights unusable.

This is where data vault modeling comes in: enabling a foundation that standardizes how data is captured, tracked, and scaled without major disruption.
As you move ahead, having a solid governance layer in place will be the key to ensuring compliance and competitiveness across the changing data landscape.
At Spiral Mantra, a leading data engineering company, our experts complement this need by providing powerful governance tools that monitor your data foundation from the beginning, making it traceable, scalable, and compliant.

