Leveraging Apache Kafka for Data Integration
Modern, microservice-based application development means applications select their data storage mechanisms according to their business needs. Since there is no consideration for having a unified database, this lack of a unified data store has resulted in organizations having multiple data sources.
Adding to this is the rapid rise of new data processing tools and frameworks, resulting in a chaotic data landscape.
In situations like the above, real-time streaming data integration platforms can make a difference. And Kafka can be a do-it-all.
In this article, we will explore how Spiral Mantra, a top
data engineering services company, utilizes Apache Kafka to derive value from data.
What is Apache Kafka
Kafka is open-source software that provides a framework for storing, reading, and analyzing streaming data. It is designed to be run in a “distributed” environment, which means that rather than sitting on one user’s computer, it works across several servers, fully utilizing the power and storage capacity that it brings.
Apache Kafka takes in information from different sources and organizes it into 'topics.' A simple example of this would be a transactional log where a grocery store records every sale.
How does Apache Kafka work?
Apache Kafka blends the two best messaging models, queuing and publish-subscribe, to offer scalability and flexibility.
In a traditional queuing system, messages are distributed across multiple consumers, which helps scale data processing efficiently. On the other hand, publish-subscribe systems allow many subscribers to get the same message while struggling to divide work among different consumers. And Apache Kafka solves this using a partitioned log model.
Here’s a glimpse of how it works:
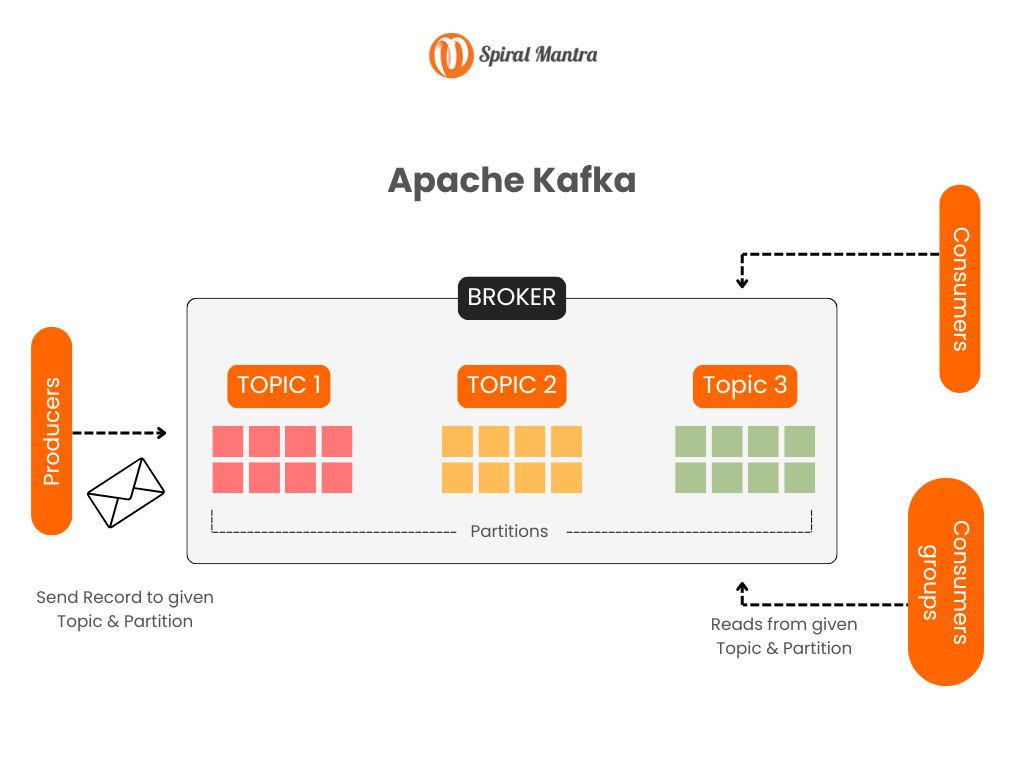
Diagram illustrating the architecture of Apache Kafka, showing how producers, brokers, topics, partitions, and consumers interact.
Apache Kafka works as a cluster that stores messages from one or more servers called producers. This data is segregated into different partitions called topics. And each topic is indexed and stored with a time stamp. It processes the real-time and streaming data along with Apache Storm, Apache HBase, and Apache Spark. There are four major APIs in Kafka:
- Producer API: used to publish a stream of records related to a Kafka topic
- Consumer API: allows an application to subscribe to multiple topics and process the stream of records
- Streams API: Converts the input stream to the output to produce results
- Connector API: allows users to automate the addition of another application or data system to the current Kafka topics
How Kafka Enables Real-Time Data Engineering
Apache Kafka plays an integral part in real-time data engineering by acting like the central nervous system of modern data architectures. With its distributed streamlining capabilities, it allows data to flow swiftly between systems, making real-time interaction smooth.
Here’s how it achieves it:
- Polish subscribe model:
Kafka uses a system where producers send data to "topics," and consumers can subscribe to read the data. This allows users to process the data in real-time, which is ideal in high data volume situations.
- Fault-tolerant architecture:
Kafka's architecture, built on a cluster of brokers and partitioned topics, ensures better scalability. Along with this, there's a provision to add more servers as data grows. Plus, Kafka keeps copies of data across multiple servers to protect against data loss.
- Easy integration with other tools:
With Kafka, connecting to databases, cloud storage, file systems, or data warehouses is easy thanks to the robust ecosystem provided by Kafka Connect.
- Better latency:
Built for latency, Kafka delivers data with low delays, so systems can react to new information instantly. This feature provides an edge for things like fraud detection or real-time application tracking.
In short, combining these features empowers data engineering services teams to offer fault-tolerant pipelines for continuously flowing data.
How Does Spiral Mantra Support Kafka Requirements?
At Spiral Mantra, a top
IT consulting services company, we specialize in designing, deploying, and optimizing real-time data pipelines powered by Apache Kafka. By leveraging open-source methods and enterprise extensions, our experts deliver solutions that enable faster decision-making. So without much ado, connect with our experts today and turn your streaming data into real business wins.


